
Новини компанії
Актуальна інформація щодо відшкодування платежів
2 Травня, 20241 хв
Сервіс Fondy є хмарним провайдером платіжних технологій і надає послуги процесування платежів за картками Visa і Mastercard, а також white label рішення в Україні та Європі. Якщо пояснити трохи простішими словами, то:
Річ у тому, що наша принципова позиція полягає в бажанні бути чесними й відкритими з нашими клієнтами й інформувати не тільки про переваги, а й про ризики нашого сервісу як інструмента розвитку власного бізнесу. Тому ми хочемо розповісти, як влаштовані наші внутрішні бізнес-процеси, що забезпечують доступність, стабільність і якість сервісу.
У нашій публічній угоді про рівень обслуговування (Service Level Agreement, SLA) ми декларуємо своїм клієнтам доступність (uptime) платіжного шлюзу на рівні 99.95%, а це означає, що:
Для 99% платежів додаткові затримки, які накладає наша система під час передачі платежу від клієнта до обслуговуючого процесингового центру або банку-еквайра, не перевищать 0,5 секунд і для 99.95% не перевищать 3 секунди.
Варто відразу зазначити, що ці вимоги поширюються лише на ту частину інфраструктури, доступність якої ми в змозі забезпечити, і не поширюються на працездатність платіжних шлюзів банків, платіжних систем, канали зв’язку за межами нашого датацентру та інші сервіси й об’єкти, на які ми не впливаємо безпосередньо.
Щоб досягти й регулярно підтримувати такий високий рівень доступності сервісу, ми виконали велику роботу з поліпшення процесів розробки, тестування, встановлення змін і моніторингу працездатності. У цій статті ми розповімо, як це у нас реалізовано і якими засобами досягається.
У розробці ми дотримуємося практики безперервної інтеграції (Continuous Integration), , що дає нам змогу оперативно виробляти доопрацьовувати вузли системи для потреб клієнтів і постачати на production-систему оновлення щодня, а нерідко й по кілька разів на день.
Свіжі зміни, внесені розробником на підставі техзавдання, проходять код ревю і процес автоматичного тестування і складання. Таким чином від моменту завершення розробки до постачання змін на production-систему можуть минути лічені хвилини.
Такі ефективні процеси в розробці дозволяють нам іти назустріч будь-яким інноваціям та експериментам, і це дуже важливо для наших клієнтів, оскільки багато з них – це бізнеси, що динамічно розвиваються і яким потрібні фінансова та технологічна гнучкість, що дають очевидну перевагу на висококонкурентному ринку.
Незважаючи на постійні зміни коду, наші програмні додатки дуже стійкі. Стабільність системи, яка зазнає частих оновлень, при цьому досягається за допомогою великої кількості автоматичних тестів, що запускаються перед кожною установкою оновлень. Жодне оновлення не поставляється на production-систему, не маючи «зелених» тестів.
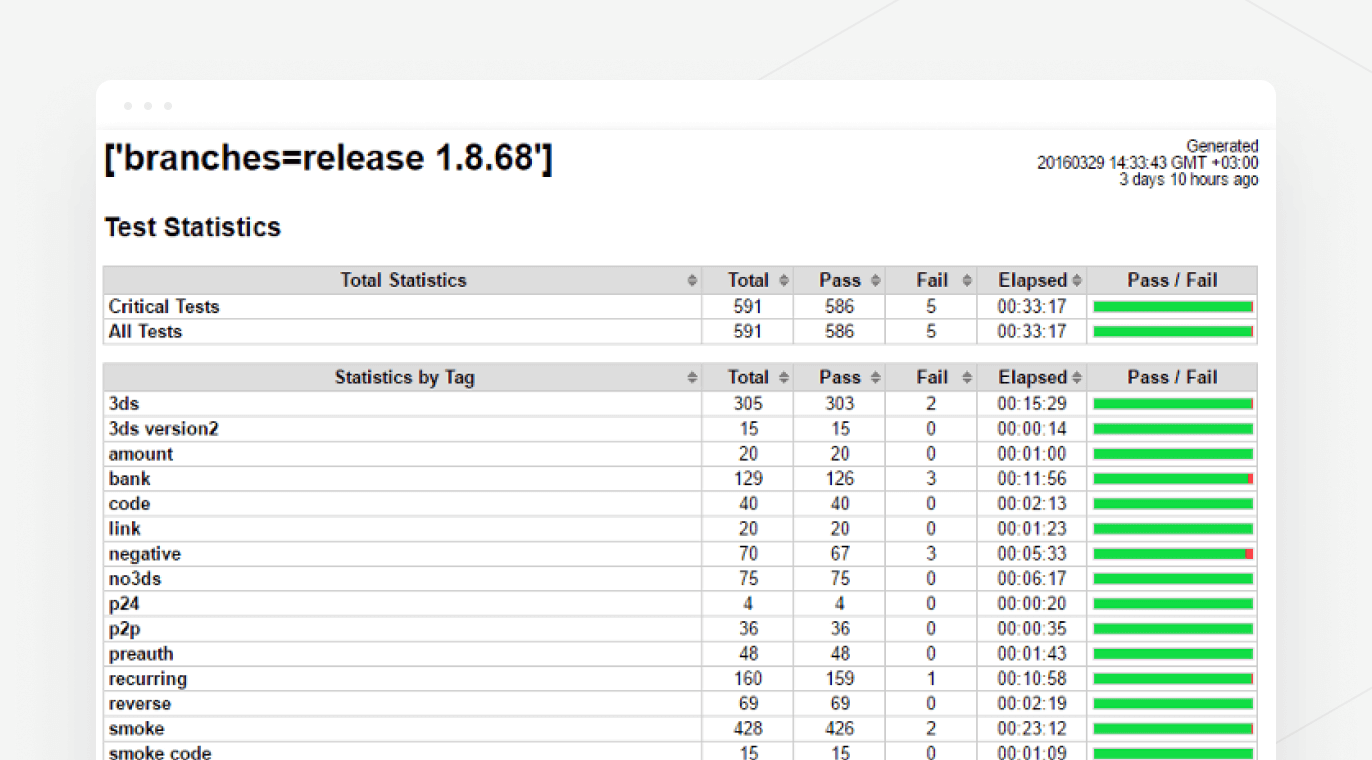
Збірка на цьому скриншоті буде позначена як broken і не потрапить на production-систему, оскільки має погані тести.
Будь-яке оновлення, встановлене на production-систему, ми спочатку розгортаємо на одному з production-серверів, на який направляється невеликий трафік платежів, до 1% від загального обсягу. При цьому відділ моніторингу та розробники, відповідальні за зміну, після установки активно моніторять наявність помилок, які додаток реєструє в автоматизованій системі стеження за помилками – Sentry. Якщо помилки є, оновлення негайно відкочується назад і відправляється на розбір причин і виправлення.
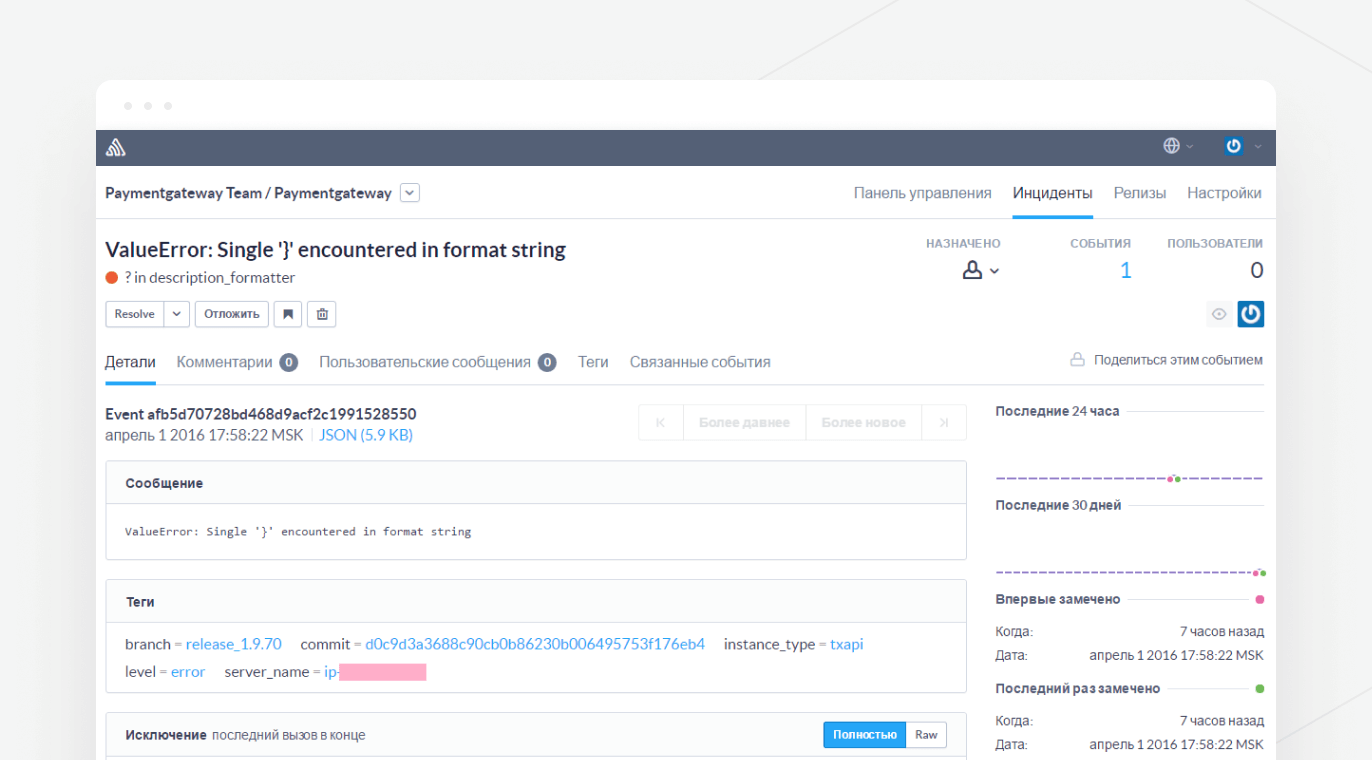
Приклад автоматичного повідомлення про помилку в системі Sentry
Якщо причиною помилки, що потрапила на production-систему, є непокритий тестами функціонал – в цьому випадку відділ QA розробляє новий автоматичний тест.
Автоматичні тести – це основний етап контролю працездатності оновлень. Крім юніт-тестів, важливу роль відіграють інтеграційні тести, і в цьому місці варто зупинитися на більш детальному описі.
Інтеграційне тестування – це перевірка коректності взаємодії системи з іншими внутрішніми й зовнішніми системами та сервісами.
Наш QA-відділ розробив велику кількість інтеграційних тестових сценаріїв, які перевіряються перед кожним оновлення production-системи. Наприклад, найкритичніша частина системи – платіжний шлюз – покритий декількома сотнями файлів тестів, які містять понад 3 000 автотестів. Так, кількість перевірок в одному регресійному тестуванні досягає 80 000. Така регресія являє собою перевірку внутрішньої працездатності всього API-шлюзу та і інтеграції з різними зовнішніми системами, такими як:
яких реалізовано в системі понад 50.
Для тестування інтеграції з зовнішніми системами, якщо така система не має стабільного тестового середовища, наші розробники реалізують так звані «заглушки» – імітацію відповіді зовнішньої системи в позитивному і негативному сценарії.
Регресія містить у собі перевірку всього платіжного функціоналу, такого як:
Наприклад, тести, які передбачають імітацію взаємодії платника в браузері з нашою платіжною сторінкою, відтворюються у всіх найбільш популярних версіях браузерів. Для Internet Explorer це від IE8 до IE11 включно.
Усі понад 80 000 тестів виконуються протягом приблизно 5 хвилин на сервері з конфігурацією 32 GB ОЗП і 8 ядрах процесора. Така швидкість виконання тестів на сервері з цілком середньою конфігурацією досягається шляхом розробки нашої команди, що дозволяє запускати тести паралельно на всіх ядрах процесорів найбільш оптимально.
Якби всі тести запускалися послідовно в один потік, то тільки один запуск регресійних тестів займав би понад годину часу. Для реалізації мультипоточних тестів і завантаження всіх CPU ми використовуємо robot framework, який підтримує запуск тестів кількома потоками.
Також для прискорення тестів ми одночасно тестуємо кілька гілок розробки в паралельному режимі, використовуючи docker – платформу для автоматичної віртуалізації додатків. За допомогою docker ми розгортаємо відразу кілька образів – копій платіжного шлюзу, розробку над якими вели й завершили різні розробники.
Результат кожного запуску тестів поширюємо серед зацікавлених співробітників у Telegram, що дає можливість оперативно виправляти тести, що «впали». Таке повідомлення містить детальну інформацію про всі тести, у тому числі скриншот і лог помилки з описом причини для розробників.
До речі, саме через Telegram у нас виконується основна розсилка повідомлень про події та інциденти системи, про які піде розповідь у наступному параграфі.
Для моніторингу працездатності системи ми використовуємо популярні засоби, такі як zabbix і Sentry, а також Business intelligence (скорочено BI) – систему власної розробки. Наша BI-система дає операторам змогу стежити за продуктивністю платіжного шлюзу, а також залежно від типу інциденту повідомляє того співробітника, якому необхідно знати про інцидент відповідно до матриці ескалації інцидентів.
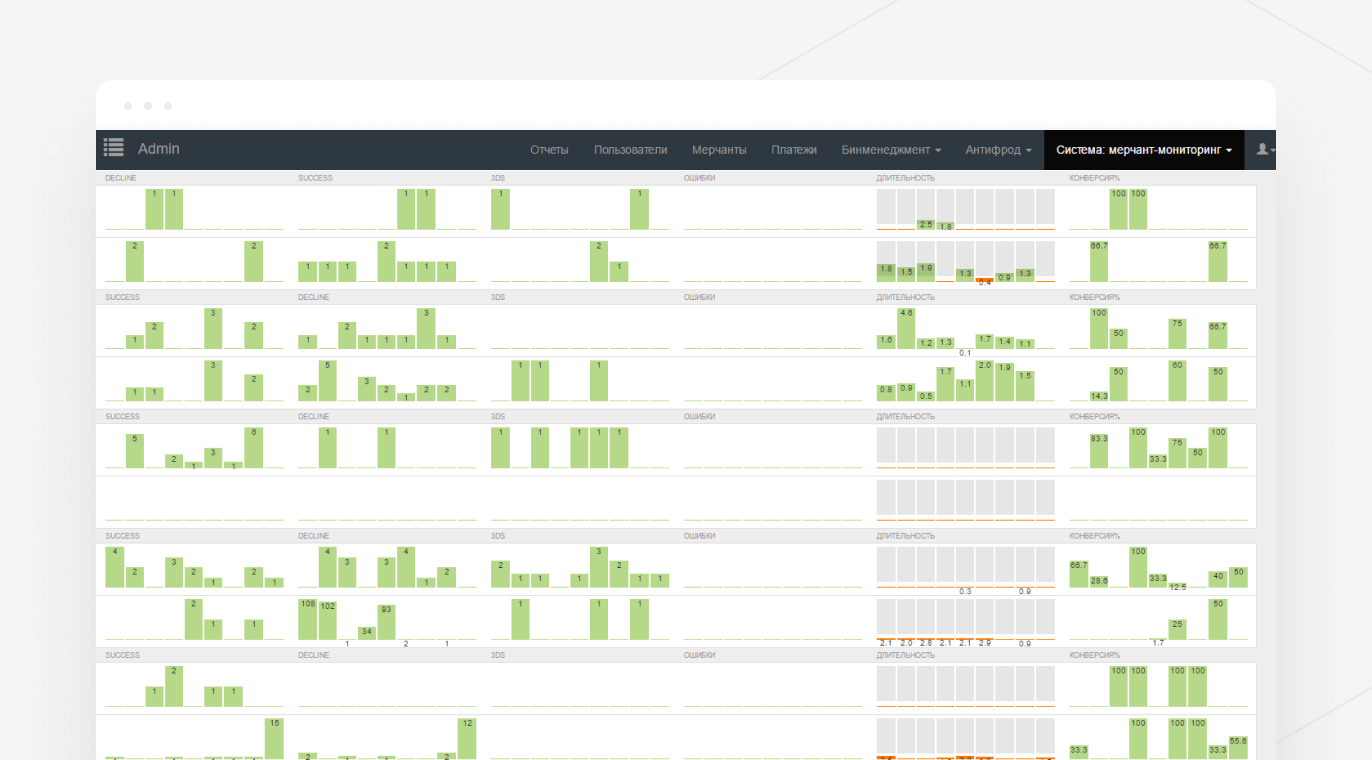
Розділ «Моніторинг мерчантів» у BI-системі показує кількість відмов, успішних платежів, помилок, швидкість проходження платежів, конверсію за найбільшими мерчантами й надсилає повідомлення в разі відхилення від норми.
Так само у нас є розділ «Моніторинг протоколів», у якому відстежується працездатність активних інтеграцій із зовнішніми системами, і в разі збою однієї з них оператор зв’язується зі службою підтримки цієї системи, щоб повідомити про проблему, або активує функцію каскадного процесингу.
Однією з дуже важливих функціональних особливостей нашої системи моніторингу є каскадний процесинг. Каскадний процесинг – це можливість мерчанта перемкнутися на протокол резервного банку-еквайра в разі збою основного. Перемикання може відбуватися або автоматично, або вручну відповідальним співробітником.

Сподіваємося, ця стаття була для вас корисна і дала деяке уявлення про Fondy як відкриту високотехнологічну компанію, котра піклується про якість свого сервісу і виконання зобов’язань перед своїми клієнтами.
Отримуйте ще більше корисної інформації про онлайн-платежі та бізнес







