Кейси
Як успішно продавати квитки на події через наші лендінги: кейс агенції The Tellers
17 Січня7 хв

Інфраструктуру будь-якої ІТ-компанії можна умовно і досить грубо поділити на дві складові: технології (програмне забезпечення, обладнання, послуги) і бізнес-процеси. Зараз інфраструктура нашої компанії працює досить стабільно, процеси дають нам змогу швидко рости, й хоча без збоїв не обходиться, трапляються вони набагато рідше, ніж на початку шляху:
Але так було не одразу. Коли ми починали створювати компанію три роки тому, у нас за плечима був десятирічний практичний досвід роботи з технологіями – і платіжними, і інформаційними, але не було досвіду побудови бізнесу та процесів із нуля. У цій колонці ми розповімо, які помилки ми допускали, з якими проблемами стикалися і як їх розв’язували під час побудови інфраструктури, яку ми маємо сьогодні.
На старті все здавалося досить простим і гранично зрозумілим. Ми знали, які технології ми будемо використовувати, і яку бізнес-модель випробовувати. З обов’язків ми визначили, що гендиректор і технічний директор закриють основні завдання менеджменту:
А в команду наймемо таких фахівців:
Далі ми приступили до пошуку потрібних співробітників. І з першими проблемами ми зіткнулися досить швидко.

Чомусь із самого початку нам не щастило з пошуком системного адміністратора. Ми працювали з трьома хлопцями дуже нетривалими періодами часу, але тільки через рік змогли знайти хорошого і надійного фахівця. Весь цей рік розгортання інфраструктури наших серверів (середовища розробки, продуктового середовища, складання релізів, системи трекінгу завдань, системи контролю версії програмного коду) йшло з перемінним успіхом і з серйозними затримками, затягуючи випуск MVP.
Додаткові складнощі створював той факт, що як платіжна платформа ми повинні проходити сертифікацію за стандартами безпеки, і адміністратор повинен мати відповідні знання і досвід, щоб розробити та впровадити апаратну архітектуру.
Порада
Поставтеся до пошуку ключових фахівців дуже відповідально. Краще найміть HR-агентство, яке буде шукати кандидатів за описаними вимогами й кваліфікацією, а вам залишиться тільки провести інтерв’ю. Якщо на етапі створення команди у вас не вистачає компетенції провести співбесіду з фахівцем, попросіть когось із ваших друзів, знайомих, партнерів з потрібною кваліфікацією зробити це для вас.
Варто пам’ятати, що команда біжить зі швидкістю найповільнішого учасника, і найнявши низькокваліфікованого або без відповідного досвіду фахівця, ви ризикуєте тим, що робота решти команди буде дуже уповільнена.
Запуск мінімально продукту, що працює, ми запланували упродовж чотиримісячного терміну. Але хоч як детально ми декомпозували завдання та обговорювали терміни реалізації з розробниками, будь-яке завдання затягувалося на період у 2-3 рази більший, ніж заявлений.
Нам ніяк не вдавалося завантажити співробітників роботою хоча б на 50%. Постійно десь виникало вузьке горлечко: то завдання ще не описане, то не готовий сервер для розгортання середовища розробки й тестування, то команда не розуміє пріоритету завдань.
В системі обліку завдань не було чітких процесів, а всі завдання валилися однієї купою, з якої розробник обирав або довільну задачу, або ту, яка йому найбільше подобається. Більшість завдань зависали на «останній милі» – начебто всі підзадачі зроблені, але зібрати всі «цеглинки» не виходить.
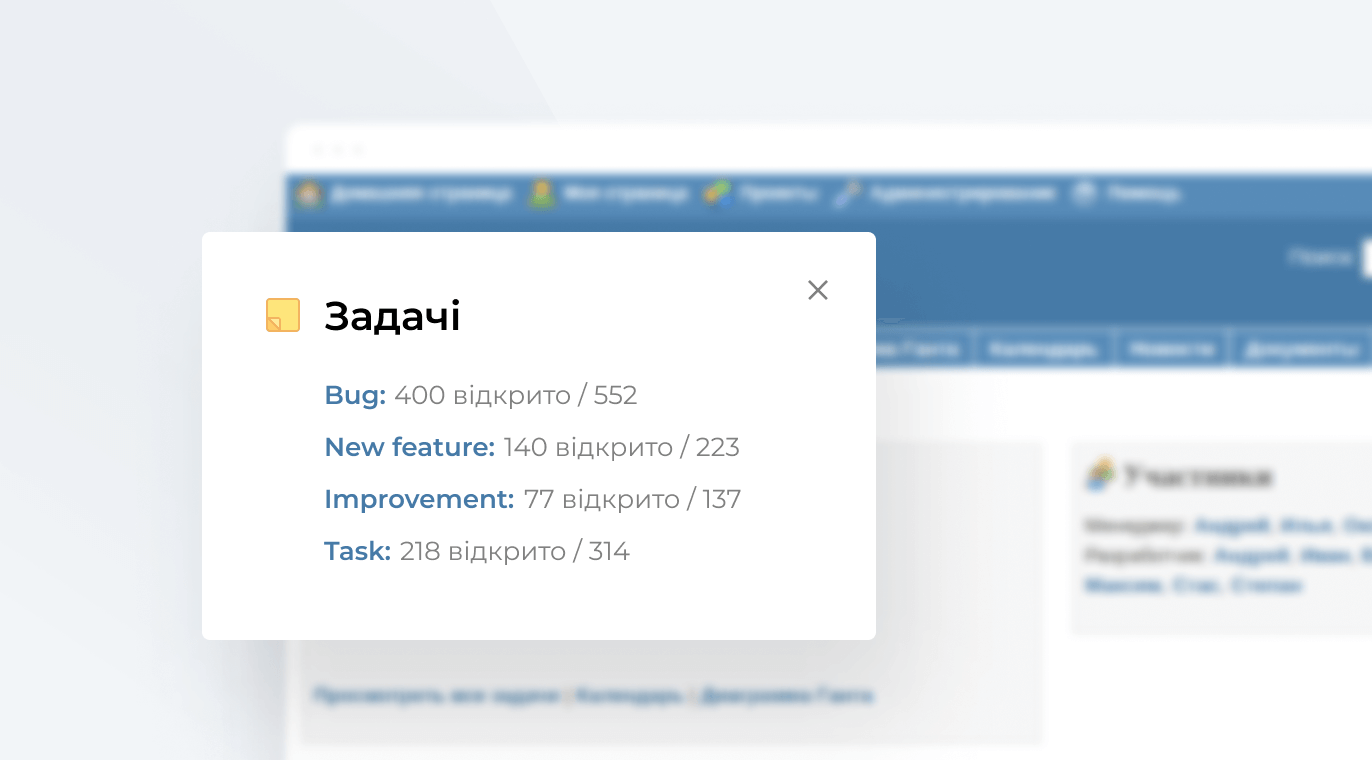
На скриншоті добре видно співвідношення незакритих завдань (400) до загальної їхньої кількості (552)
Спочатку вам здається, що щось не так із командою, і, мабуть, ви найняли слабких фахівців, і варто багатьох звільнити або замінити. Але насправді основна проблема – це відсутність бізнес-процесів.
Порада
Для побудови інфраструктури, в якій розробка йде швидко, а завдання проходять кожен етап (постановка, розробка, тестування, реліз) якнайшвидше, важливо залучити у проєкт фахівців, що мають за плечима досвід у командах, які працювали за гнучкими методологіями, таким як Agile, Scrum, XP.
З високим ступенем ймовірності в чистому вигляді жодна методологія розробки вам може не підійти й доведеться шукати золоту середину. Щоб не витратити на набивання ґуль занадто багато неоціненного для бізнесу часу, постарайтеся залучити до налагодження процесів досвідчених фахівців.
Коли процеси поступово у нас почали налагоджуватися, почали з’являтися перші клієнти, а обороти рости, черговим випробуванням для нас стало виділення ресурсів на автоматизацію процесів.
Велика частина стартапів закриваються на етапі швидкого зростання через непропорційне збільшення витрат на обслуговування бізнесу. Коли ми автоматизували систему підключення нових клієнтів до сервісу, з’ясувалося, що наша бухгалтерія перестає справлятися з фінансовими звітами й зведенням балансів, а юристи – з формуванням договорів і опрацюванням юридичних аспектів.
Перед нами постала дилема – з одного боку, ми не могли зупинити розробку релізів і кинути й без того невеликі ресурси розробки на автоматизацію бек-офісних операцій, з іншого – якби кількість наших клієнтів збільшилася вдесятеро, нам би довелося найняти ще 10-20 фахівців, що з’їло б усі наші доходи й загнало у великий мінус.
Порада
Впевнені, що багато інтернет-підприємців стикалися з проблемою, коли бухгалтер або юрист починають коригувати вектор розвитку бізнесу, вимагаючи змістити пріоритети з фронт-офісу і спрямувати їх на бек-офіс: наприклад, відмовитися від розробки важливого функціоналу, який потрібен клієнтам на сайті або в основному продукті, і зосередитися на розробці автоматизації операційних завдань.
На цьому етапі підприємству важливо розуміти, що бек-офіс не може керувати бізнесом, але й ігнорувати його потреби не можна. Варто скорегувати пріоритети й постаратися автоматизувати наймасовіші рутинні операції – в майбутньому, коли ваші конкуренти будуть вручну надсилати договори й акти виконаних робіт клієнтам, допускаючи помилки через людський фактор і витрачаючи кредит довіри, ви оціните важливість того, що зробили.
Після року роботи ми почали підраховувати, скільки нам коштує серверне обладнання і програмне забезпечення. І тут нам на руку зіграв великий досвід і вивірене роками рішення.

Ми не купували власне залізо і не будували апаратну інфраструктуру, а для розміщення серверів обрали хмару Amazon AWS, представлену в 38 зонах доступності по всьому світу, яка відповідає десяткам стандартів, норм, сертифікатів безпеки та має захист від DDoS і фізичного доступу сторонніх осіб і організацій.
Загальна кількість серверів Amazon, за даними сторонніх аналітиків, вже у 2012 році становила майже півмільйона, що дає практично необмежені можливості для масштабування. Страшно подумати, скільки потрібно ресурсів і часу витратити, щоб забезпечити хоча б малу частину того, що робить Amazon, в інфраструктурі свого проєкту власними силами.
На етапі розробки продукту нам такий вибір дав великі переваги – перші пів року все серверне обладнання нам коштувало не більш як $ 300 на місяць. Цього часу нам вистачило для розробки MVP і перевірки гіпотези нашої бізнес-моделі.
З точки зору витрат на програмне забезпечення ми завжди були прихильниками відкритого ПЗ. Існує помилкова думка, що open-source-продукти менш безпечні через свій відкритий програмний код і несуть великі ризики для бізнесу у плані вразливості, стабільності та якості технічної підтримки. Але як компанія, котра проходить щорічний аудит безпеки та щоквартальне зовнішнє сканування на спроби вторгнення, ми можемо стверджувати: відкрите ПЗ нітрохи не поступається іменитим пропрієтарним продуктам відомих софтверних гігантів, а в деяких аспектах навіть перевершує.
Порада
При розгортанні власної апаратної інфраструктури зверніть увагу на хмарні рішення. Вони зазвичай дешевші в експлуатації при невеликих обсягах і простіші в конфігурації та підтримці. У нашій ситуації один системний адміністратор у змозі забезпечувати підтримку понад 30 серверів без шкоди для загальної ефективності. Також істотно скорочують витрати open-source-продукти: бази даних, сервери додатків, CMS, CRM, системи контролю версій коду і трекінгу завдань.
Крім цього, варто приділити особливу увагу корпоративній безпеці. Останнім часом велика кількість кібератак спрямовані саме на бізнес. З цієї точки зору варто довірити свою безпеку спеціалізованим компаніям та інструментам, наприклад, системам захисту від DDoS, виявлення вторгнення, зовнішнього сканування на уразливості.
Взагалі-то падінь додатків, виходу з ладу обладнання, обриву зв’язку та інших форс-мажорних ситуацій позбутися неможливо. Навіть найнадійніші системи дають збій. Наприклад, удар блискавки у 2011 році вивів із ладу частину обладнання Amazon, і багато сайтів пішло в офлайн.

Варто завжди очікувати, що в будь-який момент будь-яка частина вашої інфраструктури може вийти з ладу: сервер, додаток, лінія телефонного зв’язку кол-центру, магістральний інтернет-провайдер. Оскільки ми підписуємо з нашими клієнтами контракт (Service Level Agreement), який гарантує рівень сервісу 99,95%, то, щоб його повною мірою виконувати, ми постаралися максимально зарезервувати всі критичні вузли нашої інфраструктури й дотримуємося стратегії «нехай падає» – на випадок падіння у нас завжди є резервні копії сервісів, які в більшості випадків включаються в роботу автоматичною системою моніторингу.
Також у компанії розроблений Disaster recovery plan – документ, який описує матрицю ескалації ІТ-інцидентів (куди бігти, що робити, яким фахівцям дзвонити), а також зони відповідальності співробітників і топменеджерів у бізнес-процесах, які були порушені.
Порада
На цей момент основною проблемою, з якою ми як підприємство, що стало на рейки бізнес-процесів, боремося – це розробка інновацій в тому ж темпі, який ми набрали на старті. Збільшуючи обороти, ми поступово починаємо занурюватися в щоденні операційні завдання, які часом займають стільки ресурсів, що основний час команди доводиться витрачати на підтримку поточних процесів, а не створення нового.
З метою адаптації до мінливих вимог бізнесу і фінтех-індустрії ми зараз розділяємо нашу команду на два підрозділи: Innovation і Operation Team. Основні завдання Operation Team полягають у підтримці рівня сервісу поточного бізнесу та забезпечення доходів теперішньої бізнес-моделі.
Натомість першочерговою для Innovation Team є підтримка швидких змін – генерація нових ідей і продуктів, впровадження інновацій, слідування трендам ринку і потребам бізнесу. Ми віримо, що і з цією проблемою нам також вдасться впоратися.
© Матеріали надані: vc.ru
Отримуйте ще більше корисної інформації про онлайн-платежі та бізнес






